3 Live Session
3.1 Live Session Schedule
- Introduction
- Recap pre- Live Session
- Build on Abundance Plots
- Drawing Hypotheses from Complex Plots
- BREAK
- What Makes a Good Visualisation?
- Collaborative task
- Share Collaborative Task Results
- BREAK
- Communicating to Different Audiences
- Visualisation Themes & Accessible Graphics
- Prepare for Challenge Task & Conclusion
3.2 Introduction
Welcome to the One Health Vector-Borne Diseases Hub Online Training. My name is Chloё, and I work with the VBD Hub to develop training and workshops, like this session today. We are also joined by our lovely demonstrators, who will be available throughout the session to provide support and answer any questions you have.
VBD Hub is a non-profit, open-source project funded by UKRI and Defra, which aims to improve accessibility and information sharing. To do this, the project builds infrastructure and tools to allow researchers to combine knowledge and share data within the VBD research community and with policymakers.
Our focus today is Visualisations in R. By the end of this training, you should be able to:
- Generate accessible visualisations to communicate complex data to different audiences and stakeholders.
- Formulate data-driven hypotheses from effective data visualisations.
- Build collaborative, professional connections within the VBD community.
In the Pre- Live Session content, you will have seen links to recap materials and cheat sheets. Feel free to use these if you need any reminders. If you need additional support, the Forum is a good first point of call where you can discuss queries with fellow participants. Our demonstrators will keep an eye on the chat during this call and can provide more support during tasks.
The written version of this content is now available on the VBD Hub website if you wish to follow along with this format. These written materials will be available for you to access in future, including the code examples. You are welcome to follow along with the walkthrough code in this Live Session, but there is no pressure, and you can have a go at the code yourself later.
If you have any technical difficulties or lose connection, try joining the meeting again when you can. If you need technical support, please contact support@vbdhub.org (note: this is only for technical support, not statistical support or questions on the course content).
We have breaks scheduled into this session, but if you need to step away for a few minutes at all, feel free to do so quietly.
3.3 Recap Pre- Live Session Content
In the Pre- Live Session content, we covered:
- Commonly used visualisations in VBD research, notably abundance plots.
- What visualisations can tell us about data, and how this can support exploratory analysis.
- How to use observed patterns from simple visualisations to formulate data-driven hypotheses.
During the tasks, we tried identifying patterns and details out the datasets and proposing hypotheses from our visualisations:
- What patterns and data details can you identify from the Monthly Mosquito Abundance across 2023 plot?
- What hypothesis do you propose for the visualisation in Task 1: Tick Abundance Across Sampling Locations?
- What hypothesis do you propose for the visualisation in Task 2: Monthly Mosquito Abundance across 2023?
3.4 Building on Abundance Plots
In the Pre- Live Session content, we covered simple abundance plots and considered how these visualisations can be used to help identify potential patterns in exploratory analysis of vector surveillance data.
However, these simple abundance plots often only tell us part of the story. In VBD research, we typically want to understand how abundance patterns vary across time, space, and species.
Common VBD research questions consider:
- Does vector abundance change throughout the year?
- Do certain locations consistently report higher vector counts?
- Do different species show distinct seasonal patterns?
In this session, we will build on the basic abundance plots introduced in the Pre- Live Session content by developing more complex visualisations using R and the ggplot2 package.
3.4.1 Abundance Across Sampling Locations
Vector populations often vary between locations. Differences in habitat, climate, host availability, and land use can all influence vector abundance. As a result, combining data from multiple sampling sites into a single trend may obscure important spatial patterns.
In the Pre-Live Session content, we plotted the abundance of ticks across two sampling locations. To do this, we used a scatter plot to view the individual observations so that we could practice identifying patterns in the data. However, in VBD research, we would typically use a bar plot to visualise abundance across multiple locations.
Let’s start by downloading mosquito_subset_wrangled.csv. Open this dataset in RStudio and load the required packages:
library("tidyverse")
mosquito_data <- read_csv("data/mosquito_subset_wrangled.csv")
#> Rows: 1991 Columns: 14
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (9): genus, species, sample_unit, sample_sex, sampl...
#> dbl (3): sample_value, sample_lat_dd, sample_long_dd
#> date (2): sample_start_date, sample_end_date
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Note: tidyverse is an all-encompassing package that contains a bunch of extra packages.
Here we will mostly be using functions from the ggplot2 and lubridate packages, but we can just load them all using tidyverse.
As our data involves multiple samples at the same site, we next want to summarise the abundance data for each location. We do this by grouping by location using the group_by() function, then summarising the abundance per location as the mean() and sd() using the summarise() function:
abundance_per_location <- mosquito_data %>%
group_by(sample_location) %>%
summarise(
mean_abundance = mean(sample_value, na.rm = TRUE),
se_abundance = sd(sample_value, na.rm = TRUE) / sqrt(sum(!is.na(sample_value)))
)We can use ggplot2 to visualise the abundance of mosquitos at multiple sampling locations by using similar code to that in the Pre- Live Session content. We start by stating our dataset and which variables we want on the x- and y-axes:
This time, instead of using geom_point(), we will use geom_col() and geom_errorbar(). This tells R that we want to plot bars with whiskers (vertical error lines):
geom_col(fill = "darkturquoise") +
geom_errorbar(aes(
ymin = mean_abundance - se_abundance,
ymax = mean_abundance + se_abundance
),
width = 0.2) +This code is starting to look heavy, but it is just building aesthetics.
In geom_col(), we can use fill to set the colour of the bars.
In geom_errorbar(), we can use aes() to set the aesthetics. In this case:
- We use
yminto set the lower end of the whisker, calculated as the mean minus the standard deviation of abundance. - We use
ymaxto set the upper end of the whisker, calculated as the mean plus the standard deviation of abundance. -
widthcontrols how wide the horizontal lines are at either end of the whisker.
The final chunk of code is adding labels using labs() - this is the same as we practised in the Pre- Live Session content:
labs(
title = "Mean Abundance of Culex pipiens Across Locations",
x = "Sampling Location",
y = "Mean Abundance"
)If we piece those chunks of code together, we can generate our visualisation:
abundance_plot_across_locations <- ggplot(
abundance_per_location,
aes(x = sample_location, y = mean_abundance)
) +
geom_col(fill = "darkturquoise") +
geom_errorbar(
aes(
ymin = mean_abundance - se_abundance,
ymax = mean_abundance + se_abundance
),
width = 0.2) +
labs(
title = "Mean Abundance of Culex pipiens Across Locations",
x = "Sampling Location",
y = "Mean Abundance"
)
abundance_plot_across_locations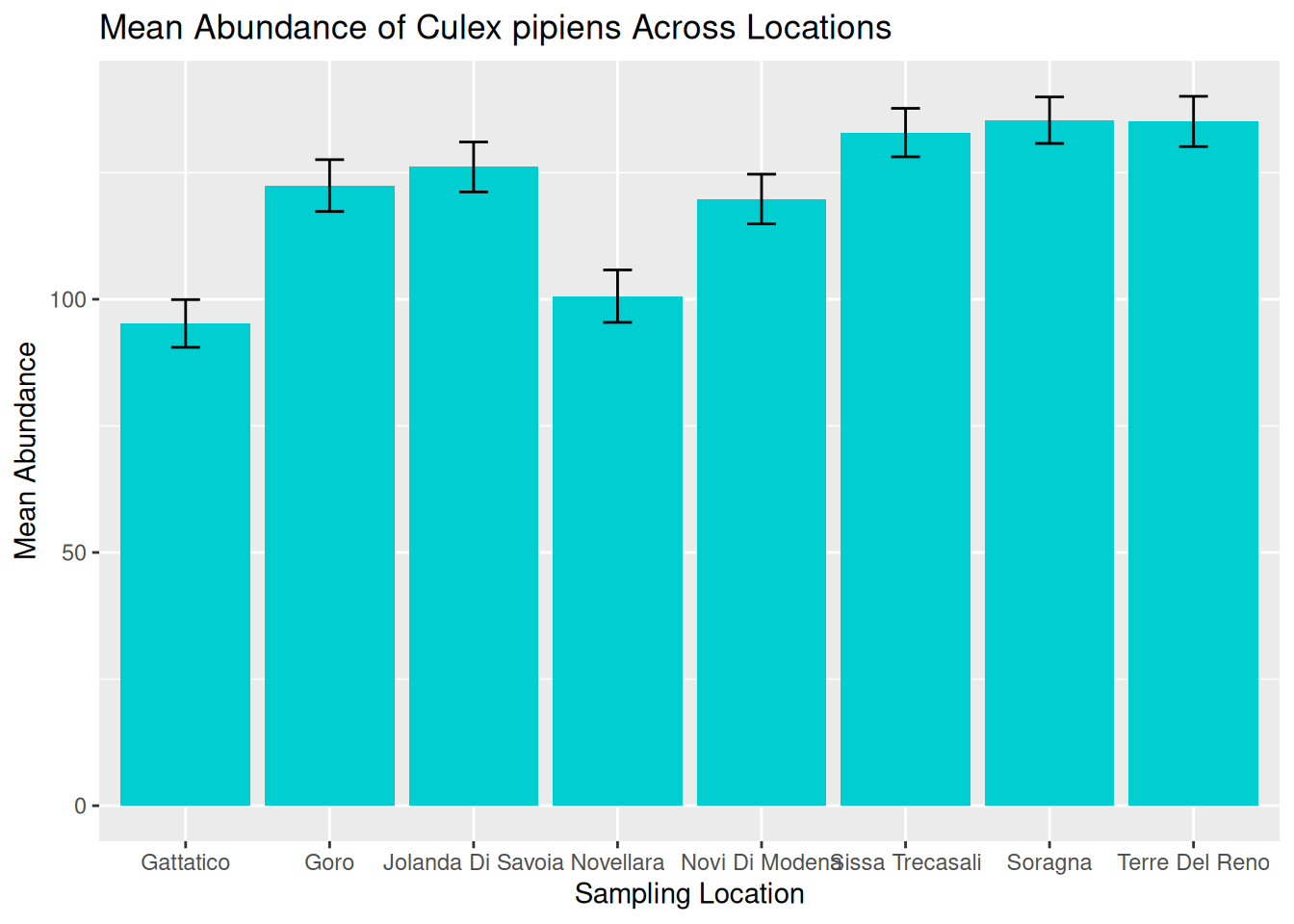
Tip: Remember to save your graphic:
ggsave("daily_abundance_all.pdf", plot = daily_abundance_plot_all)We can now use this visualisation to compare abundance patterns across sampling sites:
- Mean abundance varies across locations, with Sorragna and Terre Del Reno showing the highest mean mosquito abundance, and Gattatico showing the lowest mean mosquito abundance.
- There is a lot of variation within each location. This is consistent across the dataset, suggesting natural variation in the data to be explored further.
Visualisations such as this can help researchers identify potential hotspots of vector activity and guide further investigation into the ecological factors driving these patterns. For our graphic, we can see a lot of variation within each location. One way to assess this in more detail is to consider abundance over time.
3.4.2 Abundance Over Time: Time-Series
A time-series plot shows observations across a continuous timeline, allowing us to see how abundance changes over time. These visualisations can help us identify:
- Seasonal trends in abundance.
- Periods of rapid population growth or decline.
- Potential sampling gaps or inconsistencies.
Understanding these patterns is particularly important in VBD research because vector populations are often strongly influenced by seasonal environmental conditions, including temperature, rainfall, and host availability.
In the Pre- Live Session content, we grouped observations by months. We are now going to visualise abundance as a true time-series by using the sampling date to show how abundance changes over continuous time for a single species.
Later in this session, we will consider abundance over multiple locations, but for now, let’s filter the data to visualise abundance over time at a single location - Goro:
When working with time-series data, it is useful to understand how R stores and processes dates. In a dataset, dates are typically stored as characters (plain text format). Although an entry like “2023-06-15” might look like a date to us, R does not automatically recognise this as a date and will treat it as a character string.
When we generate a plot, ggplot2 will respond to how a variable is stored. For example, variables in character format will be plotted as categorical, whereas variables in date format will be plotted along a continuous time axis.
In time-series visualisations, a continuous time axis ensures:
- Observations are plotted in chronological order.
- Spaces between data points reflect true time differences.
- Trends over time can be interpreted accurately.
To convert our date column from characters to date objects, we can use the as.Date() function:
mosquito_data_goro$sample_start_date <- as.Date(mosquito_data_goro$sample_start_date)The as.Date() function is used to convert a column into a proper date format so that R and ggplot2 can recognise these as dates.
Frequent mistake: If dates are messy, the plot will look messy. Ensuring the date column is in the correct data format means that R knows how to process the data correctly.
We can then build our visualisation in ggplot2, as we did in the Pre- Live Session content. We start by stating our dataset and which variables we want on the x- and y-axes:
In the Pre- Live Session content, we used geom_point() to generate a simple abundance plot with scatter points so that we could see the individual observations across specific months (categories). For true time-series, we want to visualise time as a continuous measure across observation dates, so it is more appropriate to use a line plot. To do this, we replace geom_point() with geom_line():
We can start to consider the visual appeal of our graphics, starting with the colour of the line. Within the geom_line() function, we can set the colour of the line:
ggplot(mosquito_data_goro, aes(x = sample_start_date, y = sample_value)) +
geom_line(colour = "darkturquoise") +Setting line colours can be useful when plotting multiple lines on the same graphic. We will further develop this idea later in this session.
Tip: Although visually pleasing graphics are nice to look at, it is often more important to understand how to develop effective visualisations that accurately communicate your data and patterns.
We will cover both skills in this workshop, but in general, try to consider that a plain but clear and interpretable graphic is often more useful than a flashy graphic with poor accuracy and readability.
We can then add our title and axes labels using labs() as we did in the Pre- Live Session content, and generate our abundance plot:
time_series_plot_goro <- ggplot(mosquito_data_goro, aes(x = sample_start_date, y = sample_value)) +
geom_line(colour = "darkturquoise") +
labs(
title = "Abundance of Culex pipiens Over Time",
x = "Date",
y = "Abundance"
)
time_series_plot_goro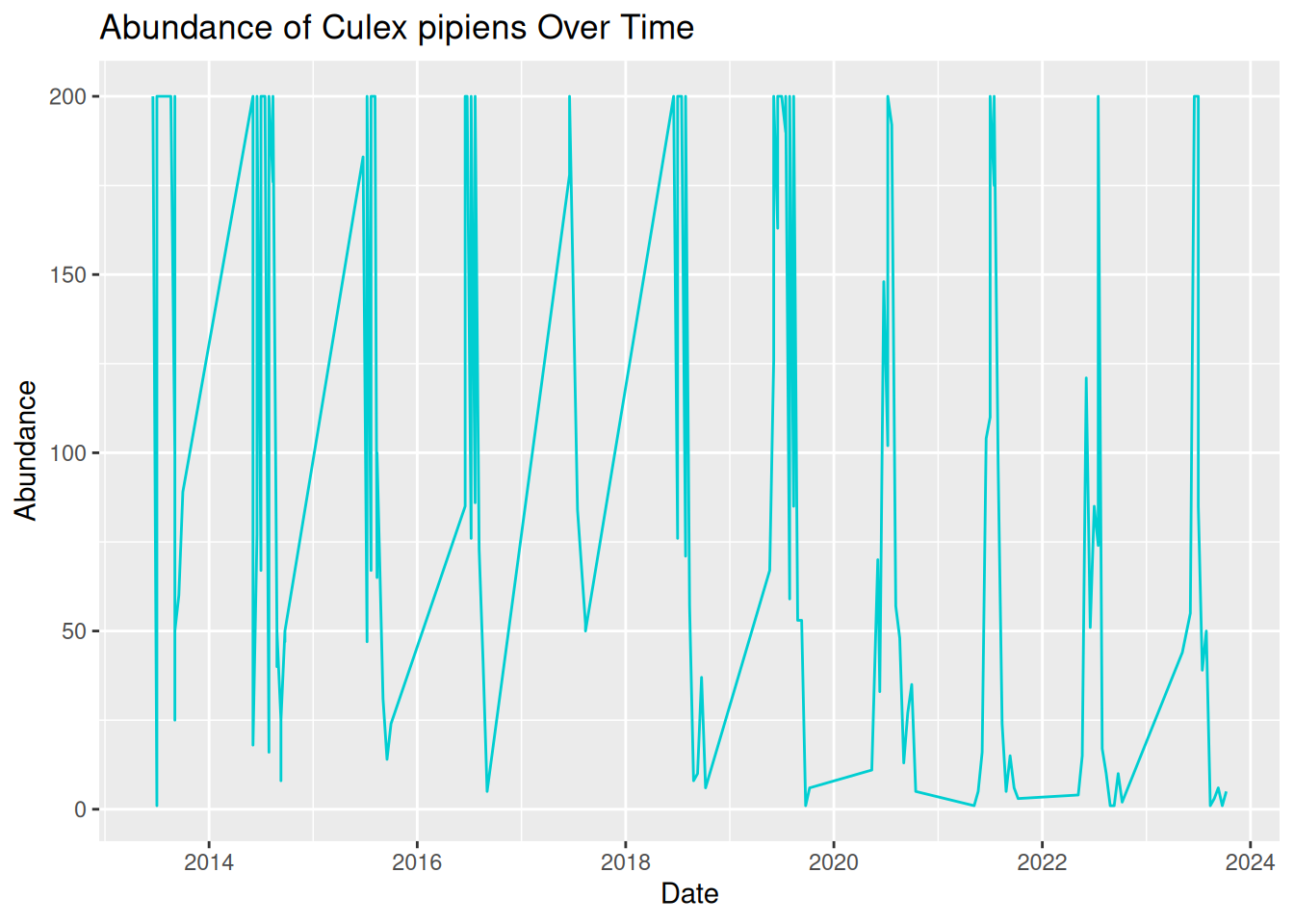
Oh dear, this graphic looks rather messy! Although we have used the correct code and ensured our date column is in the correct format, our visualisation is still difficult to read and interpret. This is because real-world VBD data often includes multiple samples collected on the same data. To create a more effective time-series visualisation, we need to summarise these samples into a single value per time point:
daily_abundance_goro <- mosquito_data_goro %>%
group_by(sample_start_date) %>%
summarise(total_abundance = sum(sample_value, na.rm = TRUE))We can now use the summarised daily abundance data to try plotting again, this time using daily_abundance_goro as our data and total_abundance on our y-axis:
daily_abundance_plot_goro <- ggplot(daily_abundance_goro, aes(x = sample_start_date, y = total_abundance)) +
geom_line(colour = "darkturquoise") +
labs(
title = "Abundance of Culex pipiens Over Time",
x = "Date",
y = "Abundance"
)
daily_abundance_plot_goro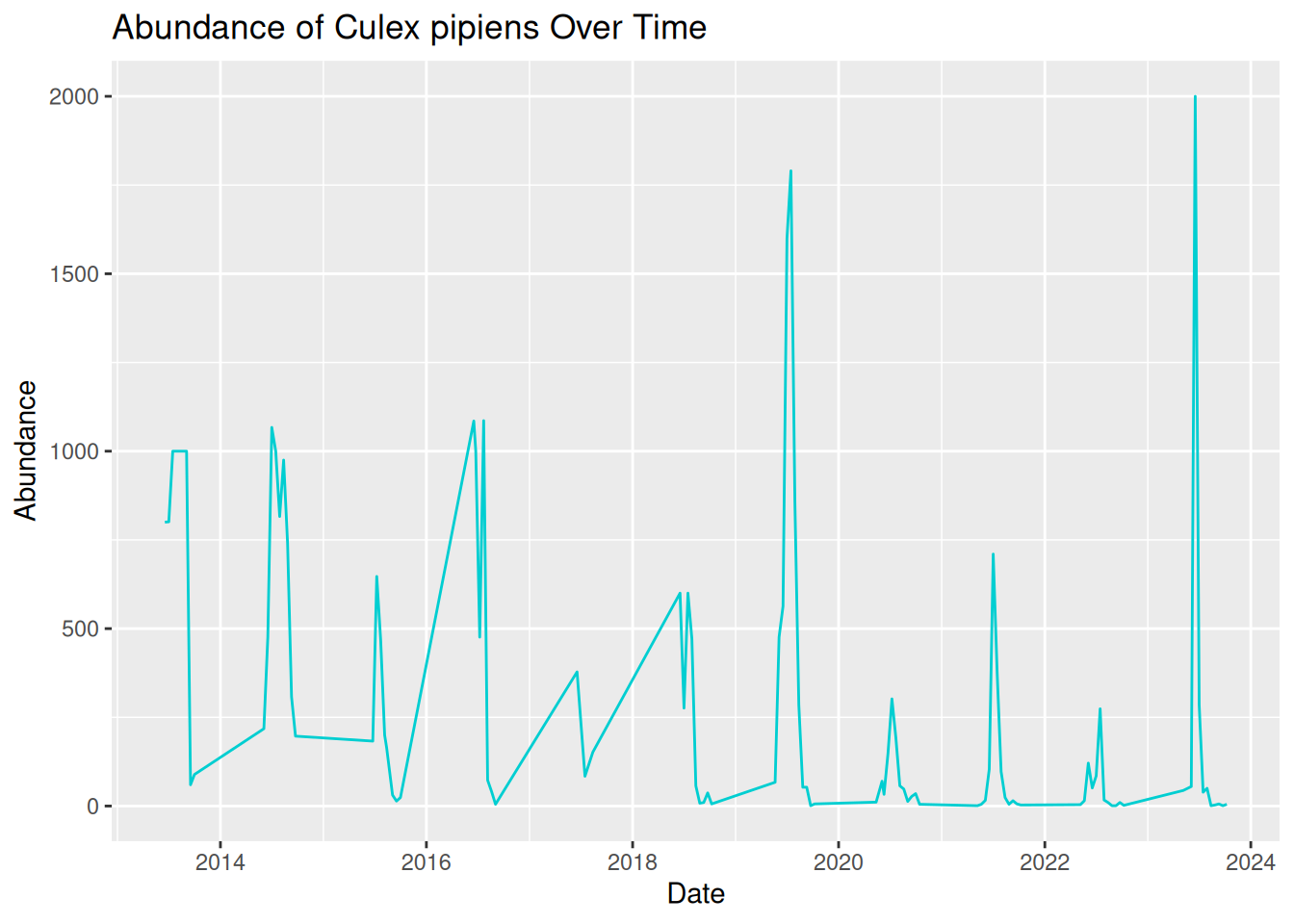
This is much better! Our visualisation effectively shows the trend of mosquito abundance over time at our selected location.
In this plot:
- The x-axis represents the continuous sampling time period.
- The y-axis represents mosquito abundance.
- The line connects daily abundance over continuous time.
Time-series abundance plots like this one can provide useful insights into seasonal dynamics within vector populations. These can be useful when identifying patterns in our data:
- Strong seasonality - abundance spikes in summer each year.
- Year-to-year variability - some years have higher peaks than others.
- General trend - although abundance varies within the year, the peak each year seems to be increasing over time.
Tip: Remember to save your graphic:
ggsave("daily_abundance_all.pdf", plot = daily_abundance_plot_all)3.4.3 Abundance Across Multiple Locations Over Time
In the previous examples, we have visualised abundance at multiple sampling locations, and abundance changes over time for a single location, but what if we combine these to look at abundance across multiple locations over time?
In VBD research, data are commonly collected from multiple sampling sites, and we often want to compare how vector abundance varies across these locations simultaneously.
We can achieve this by developing our time series plot to include multiple locations. Before, we grouped the data by the date alone, but this time, we want to group the data by both sampling location and date, so that abundance is calculated separately for each location over time:
daily_abundance_all_locations <- mosquito_data %>%
group_by(sample_location, sample_start_date) %>%
summarise(total_abundance = sum(sample_value, na.rm = TRUE),
.groups = "keep")Frequent mistake: Be sure to add .groups = "keep" when adding multiple variables to group_by. Without this, some packages in R will drop variables after the first group_by variable, and you will see a message like this:
summarise() has grouped output by 'sample_location'. You can override using the .groups argument.
To visualise the data, we will generate a time-series abundance plot as we did before, but this time, we will use the group = sample_location argument within aes() to tell R that we want a separate line for each different sampling location:
daily_abundance_plot_all <- ggplot(
daily_abundance_all_locations,
aes(x = sample_start_date, y = total_abundance, group = sample_location)
) +
geom_line(colour = "darkturquoise") +
labs(
title = "Abundance of Culex pipiens Across Locations Over Time",
x = "Date",
y = "Abundance"
)
daily_abundance_plot_all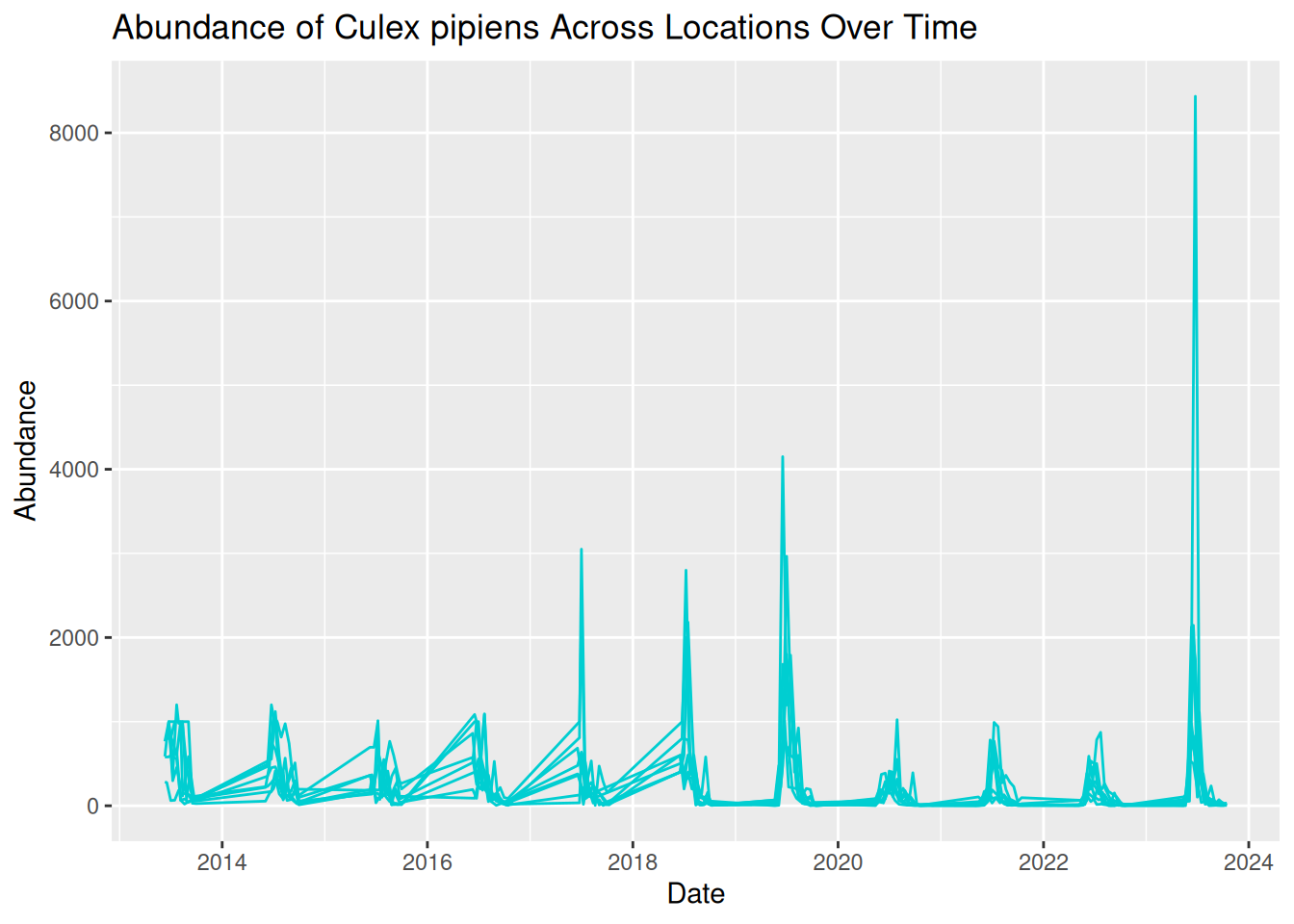
This is the visualisation we wanted, but it looks a bit messy. All the lines are displayed in the same colour, which makes the plot difficult to read. We can see patterns of abundance change over time, but it is difficult to distinguish between different locations.
What we are seeing here is that more complex visualisations are not always better visualisations, especially if interpretation is limited.
One option to improve our visualisation and to help distinguish between locations is to assign a different colour to each sampling location. To do this, we map sampling_location to the colour aesthetic within aes(), rather than assigning the line colour within geom_line():
daily_abundance_plot_all <- ggplot(
daily_abundance_all_locations,
aes(x = sample_start_date, y = total_abundance, colour = sample_location)
) +
geom_line() +
labs(
title = "Abundance of Culex pipiens Across Locations Over Time",
x = "Date",
y = "Abundance",
colour = "Sampling Location"
)
daily_abundance_plot_all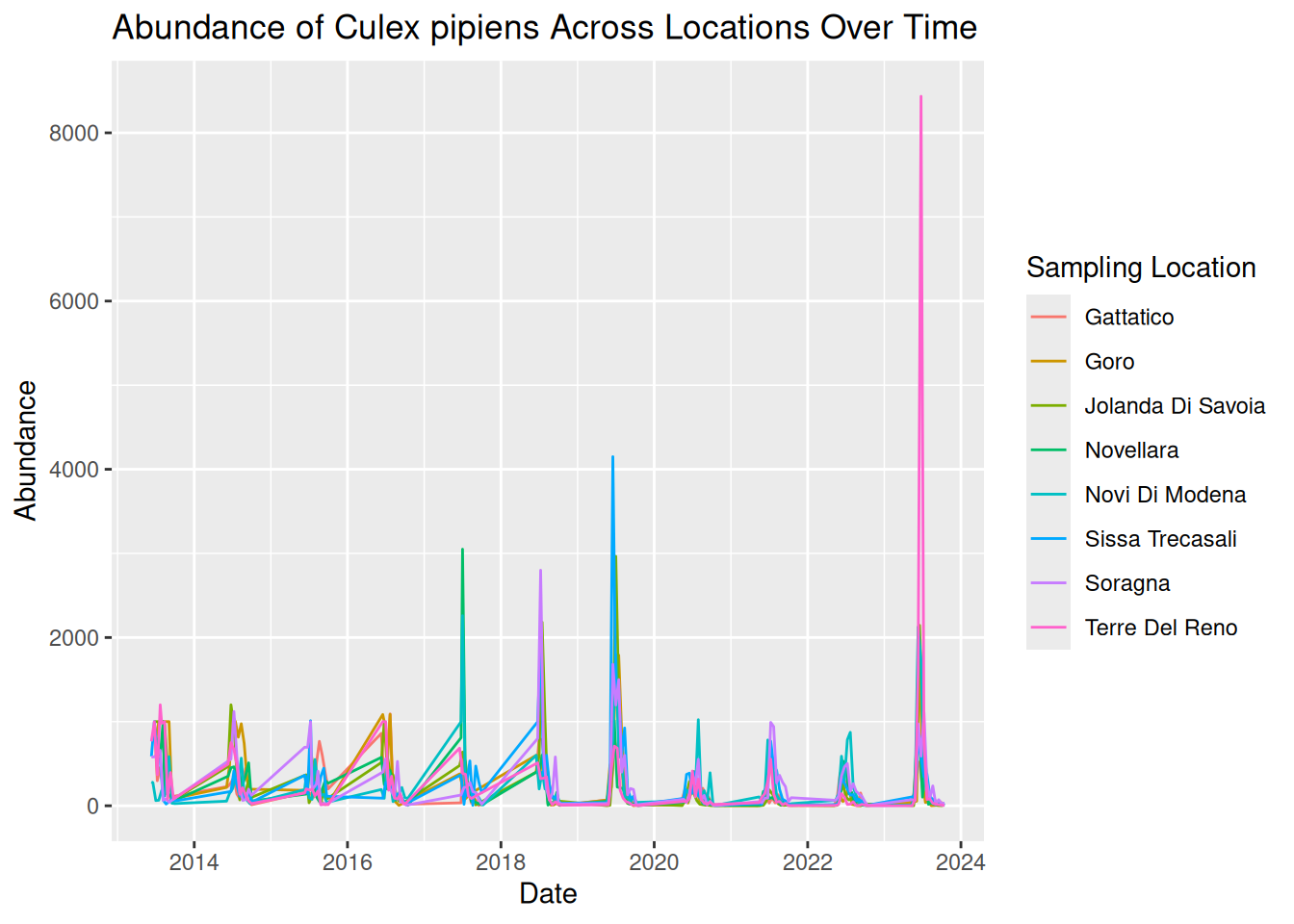
By adding colour, each line now represents a different sampling location more clearly, with a key detailing the line colour for each location. This makes it easier to identify patterns across locations.
By plotting both location and time together, we can identify patterns in the data:
- Strong seasonal patterns across all locations, with patterns of sharp peaks and rapid declines each year.
- Although trends over time are similar across locations, some show higher abundance than others.
- Some extreme peaks in abundance stand out compared to the general trends. These may represent natural variation, such as optimal conditions and location for mosquito breeding, or these observations could be outliers. Further testing would be needed to assess this.
Tip: Remember to save your graphic:
ggsave("daily_abundance_all.pdf", plot = daily_abundance_plot_all)However, while using colour can definitely improve graphics, visualisations can still feel overcrowded when too many groups are displayed together. For example, our visualisation plots 8 different locations on the same graph. Overlapping lines and similar temporal patterns can make it difficult to fully interpret the data.
Additionally, using colour alone can cause difficulties with accessibility to all audiences, which we will address later in this session.
3.4.4 Using Faceting to Improve Clarity
One useful solution to this overcrowding is faceting, a feature in ggplot2 that splits a single plot into multiple smaller panels.
Each panel displays a subset of the data, allowing patterns to be compared side-by-side without overlapping elements. By separating the data into smaller panels, we can often reveal patterns that might otherwise be hidden within a crowded visualisation.
Faceting is particularly useful when:
- Comparing multiple species.
- Comparing sampling sites.
- Exploring patterns across environmental conditions.
We can apply faceting to our previous time-series visualisation to separate each sampling location into its own panel, rather than using different colours. This directly addresses the overlapping lines, improving the overall clarity and readability.
To do this, we add facet_wrap() to our existing code, which tells R that we want to generate several panels separated by location:
daily_abundance_plot_faceted <- ggplot(
daily_abundance_all_locations,
aes(x = sample_start_date, y = total_abundance)
) +
geom_line(colour = "darkturquoise") +
facet_wrap(~ sample_location) +
labs(
title = "Abundance of Culex pipiens Across Locations Over Time",
x = "Date",
y = "Abundance"
)
daily_abundance_plot_faceted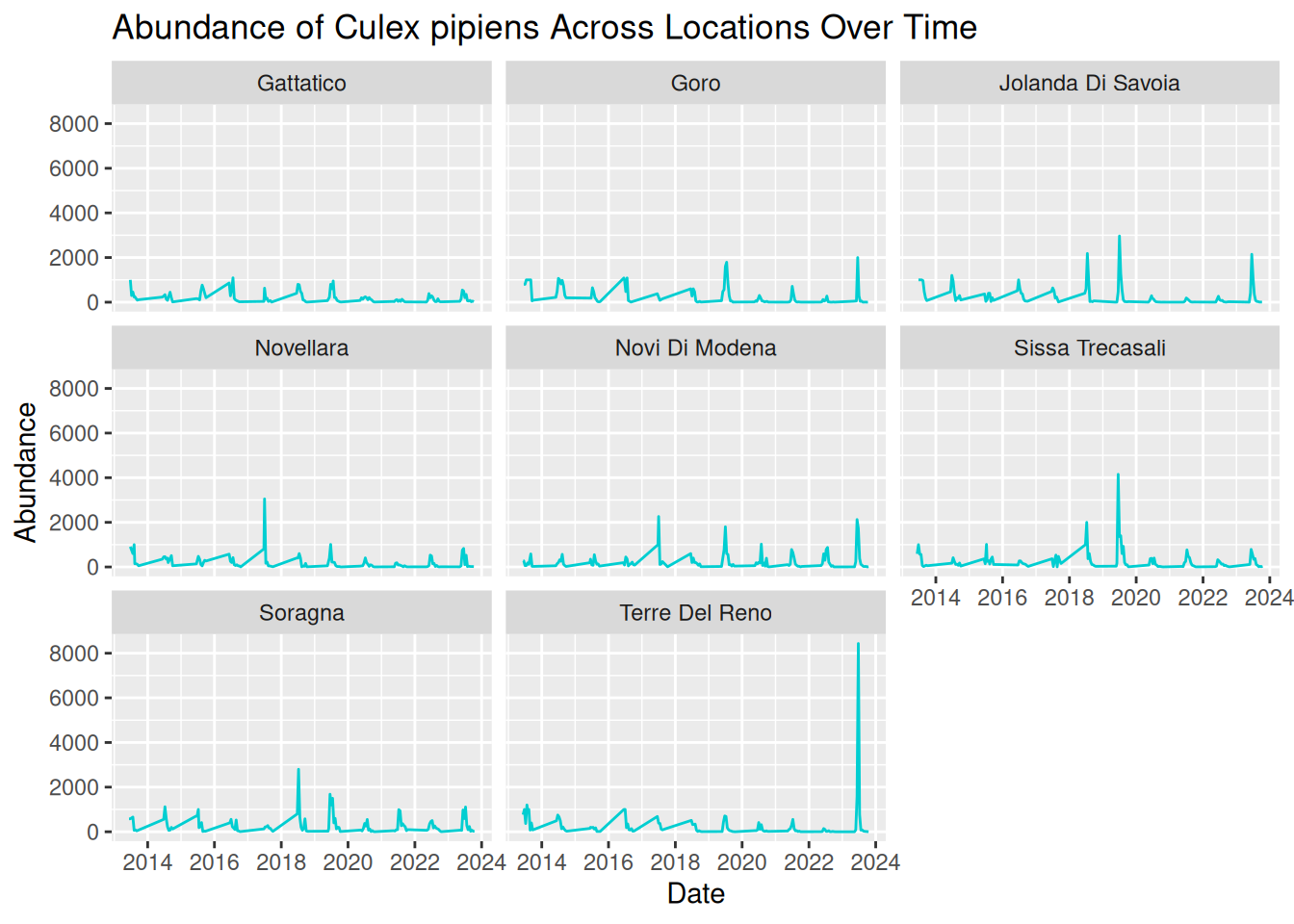
By separating each sampling location into its own panel, the patterns in the data become much clearer:
- Seasonal trends are still evident across all locations, but we are now able to see how these patterns vary between locations more easily.
- Differences in abundance magnitude are much clearer, with some locations consistently showing higher peaks, and others reflecting relatively low abundance across the time-series.
- Extreme peaks can be clearly associated with specific locations without overlapping lines hiding these observations.
Overall, faceting improves clarity by reducing visual clutter and allowing direct comparisons between locations. This makes it easier to interpret both independent trends per location and compare patterns across multiple locations.
Optional refinement: In our current visualisation, all panels share the same y-axis scale, which is good for comparisons. However, this scale also means extreme peaks are visually dominant, and locations with smaller peaks look flat in comparison.
We can add scales = "free_y" within facet_wrap() to adjust the y-axis scales across the panels, allowing us to visualise the patterns per location in greater detail:
daily_abundance_plot_faceted_Y <- ggplot(
daily_abundance_all_locations,
aes(x = sample_start_date, y = total_abundance)
) +
geom_line(colour = "darkturquoise") +
facet_wrap(~ sample_location, scales = "free_y") +
labs(
title = "Abundance of Culex pipiens Across Locations Over Time",
x = "Date",
y = "Abundance"
)
daily_abundance_plot_faceted_Y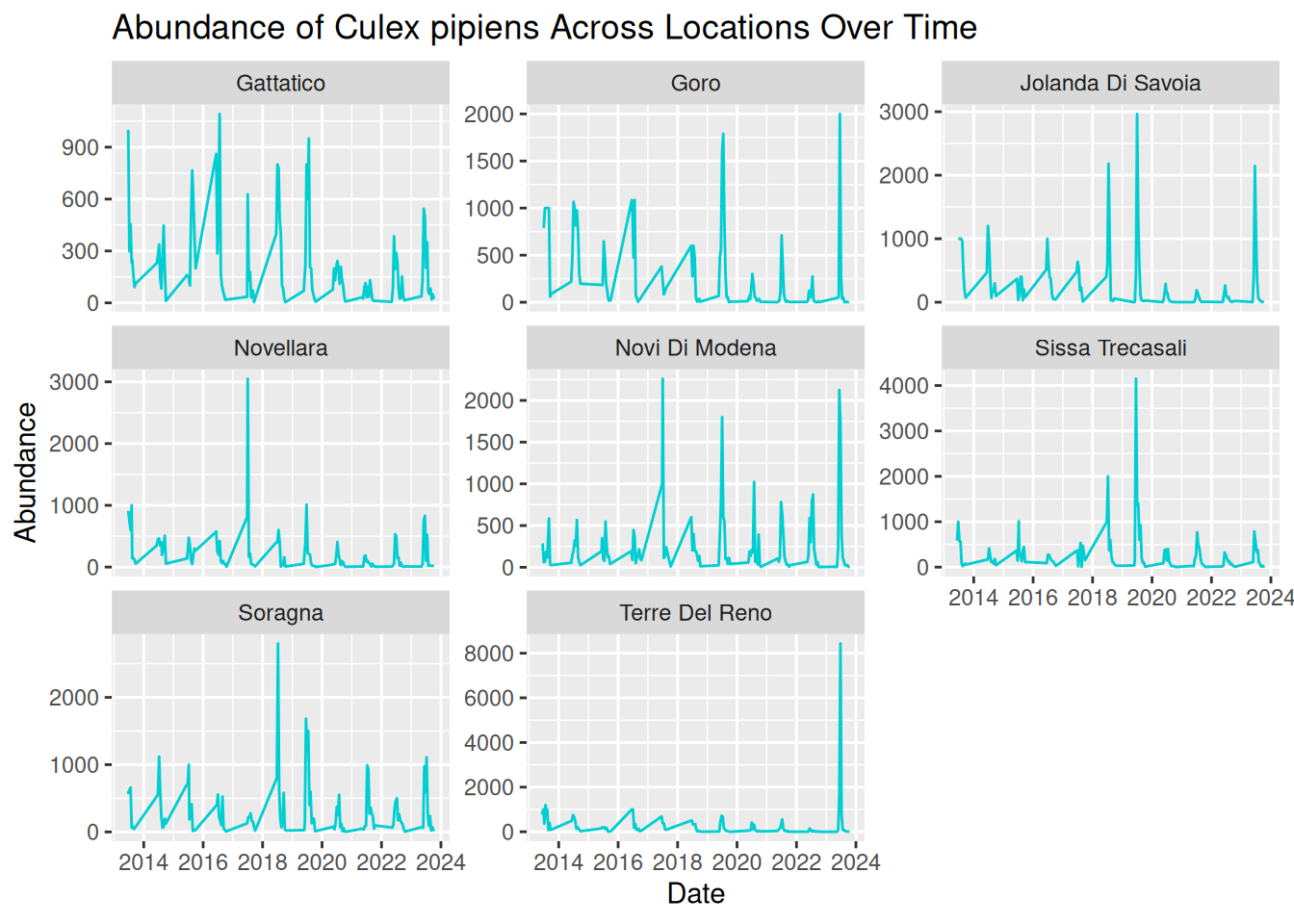
3.4.5 Applying These Principles to Multiple Species and Datasets
Various vector species can exhibit very different ecological behaviours. For instance:
- Some species may emerge earlier in the season.
- Some may reach a higher peak abundance.
- Others may vary in abundance depending on particular habitats or hosts.
Understanding these differences is important when studying disease transmission dynamics. Luckily, you already have the tools to visualise these patterns!
In the last example, we visualised abundance over time, grouped by sampling location. For multiple species comparisons, we do the same abundance plots but grouped by species, rather than sampling location.
This is an important advantage of using flexible tools such as R and ggplot2. Once we understand the principles of building effective visualisations, we can apply them to many different datasets and research questions.
3.5 Drawing Hypotheses from Complex Visualisations
In the Pre- Live Session content, we looked at how simple visualisations can help us identify patterns in data and develop initial hypotheses.
Real-world VBD datasets are often complex, containing observations collected across multiple locations, species, and time periods. When visualised, these datasets can reveal more nuanced patterns, allowing researchers to develop more detailed and targeted hypotheses.
Let’s have a go at building on the earlier examples and consider how complex visualisations can help us refine our scientific questions. Based on this visualisation, what hypotheses could you generate about mosquito abundance?
daily_abundance_plot_faceted_Y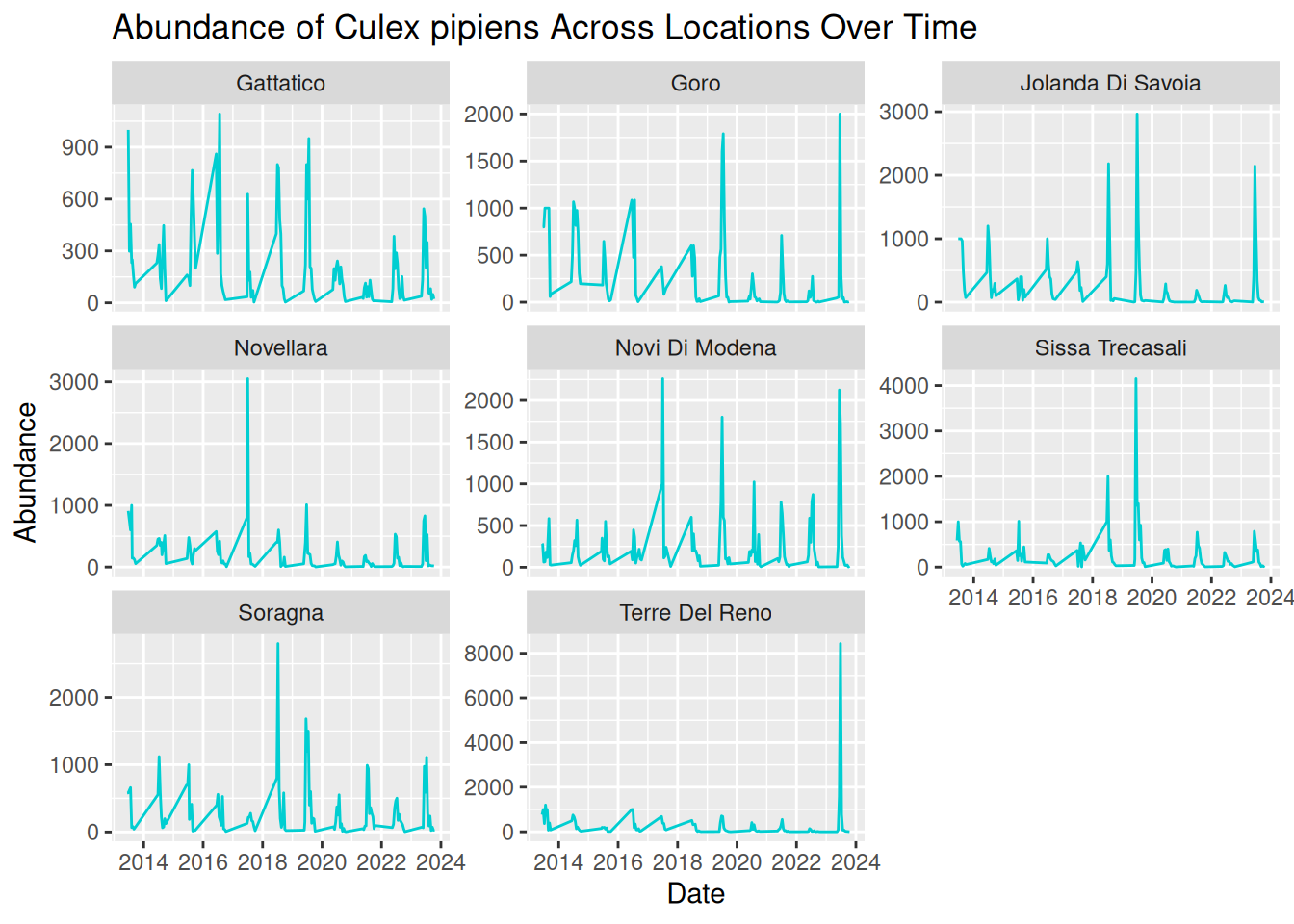
Tip: Consider these prompts to formulate your hypotheses:
- Patterns over time
- Differences between locations Unusual observations
- Alternative explanations for the same pattern
While visualisations are extremely useful for identifying patterns, it is important to remember that they do not by themselves confirm causal relationships. Instead, they provide a starting point for developing hypotheses that can later be tested using statistical models, experimental studies, or additional data collection.
In practice, this process often involves several steps:
- Identifying patterns in the visualisation.
- Proposing possible explanations for those patterns.
- Considering alternative explanations.
- Designing analyses or studies that could test these hypotheses.
By working through this process, researchers can move from simple visual observations to well-defined scientific questions that contribute to a deeper understanding of vector ecology and disease transmission dynamics.
3.6 What Makes a Good Visualisation?
So far in this workshop, we have focused on how to create visualisations that explore patterns in vector surveillance data. However, as we have seen, not all visualisations communicate information clearly or effectively.
A well-designed visualisation should help the viewer quickly understand the key message of the data. Poorly designed visualisations, on the other hand, can be confusing, misleading, or difficult to interpret.
We will now explore the characteristics that contribute to effective data visualisations, based on your own experience and the visualisations you have previously seen. Consider what you think makes a good or bad visualisation.
Some features commonly associated with good visualisations include:
- Clarity - the plot communicates its message quickly and clearly.
- Accuracy - the visual representation reflects the underlying data correctly.
- Simplicity - unnecessary elements that distract from the data are avoided.
- Accessibility - the visualisation can be interpreted by a wide audience.
For example, clear axis labels, readable text, and appropriate colours all contribute to making a visualisation easier to interpret.
Conversely, poor visualisations may include limitations such as:
- Unclear or missing axis labels.
- Confusing colour schemes.
- Unnecessary visual elements.
- Misleading scales or distorted representation of data.
These issues can make it difficult for viewers to understand the patterns being communicated by the visualisation.
3.7 Collaborative Task: Improving a Flawed Visualisation
To explore these concepts in practice, we will now work collaboratively to improve a series of intentionally flawed visualisations.
We will split into breakout rooms, where each group will be given one visualisation that contains a different common visualisation mistake. These may include:
- Confusing colour schemes.
- Unclear axis labels.
- Inappropriate chart types.
- Missing legends.
- Excessive visual clutter.
The goal of the activity is to identify the problems within the visualisation and work together to redesign it so that the underlying dataset and associated patterns are communicated more clearly.
You will need to work together to:
- Identify what makes the visualisation difficult to interpret.
- Modify the code to create an improved version of the visualisation.
- Be prepared to briefly explain the changes your group made.
Note that there is no single “correct” solution. The goal of this task is to think critically about how visualisation design choices influence how data is interpreted.
Tip: Consider questions such as:
- What is the main message of the visualisation?
- What aspects of the current design make the message difficult to interpret?
- How could the visualisation be improved?
This activity contributes to experience in collaborative critique, a useful skill in research settings. Real-world visualisations are often refined through feedback from colleagues and collaborators.
3.7.1 Graph 1
Dataset: group1_and_2_data.csv
Flawed code:
library("tidyverse")
group1_data <- read.csv("data/group1_and_2_data.csv")
group1_data$sample_start_date <- as.Date(group1_data$sample_start_date)
daily_abundance_all <- group1_data %>%
group_by(sample_location, sample_start_date) %>%
summarise(total_abundance = sum(sample_value, na.rm = TRUE),
.groups = "keep")
group1_plot <- ggplot(daily_abundance_all,
aes(x = sample_start_date, y = total_abundance, group = sample_location)) +
geom_line(colour = "darkturquoise") +
labs(
title = "Mosquito Abundance Over Time",
x = "Date",
y = "Abundance"
)
group1_plot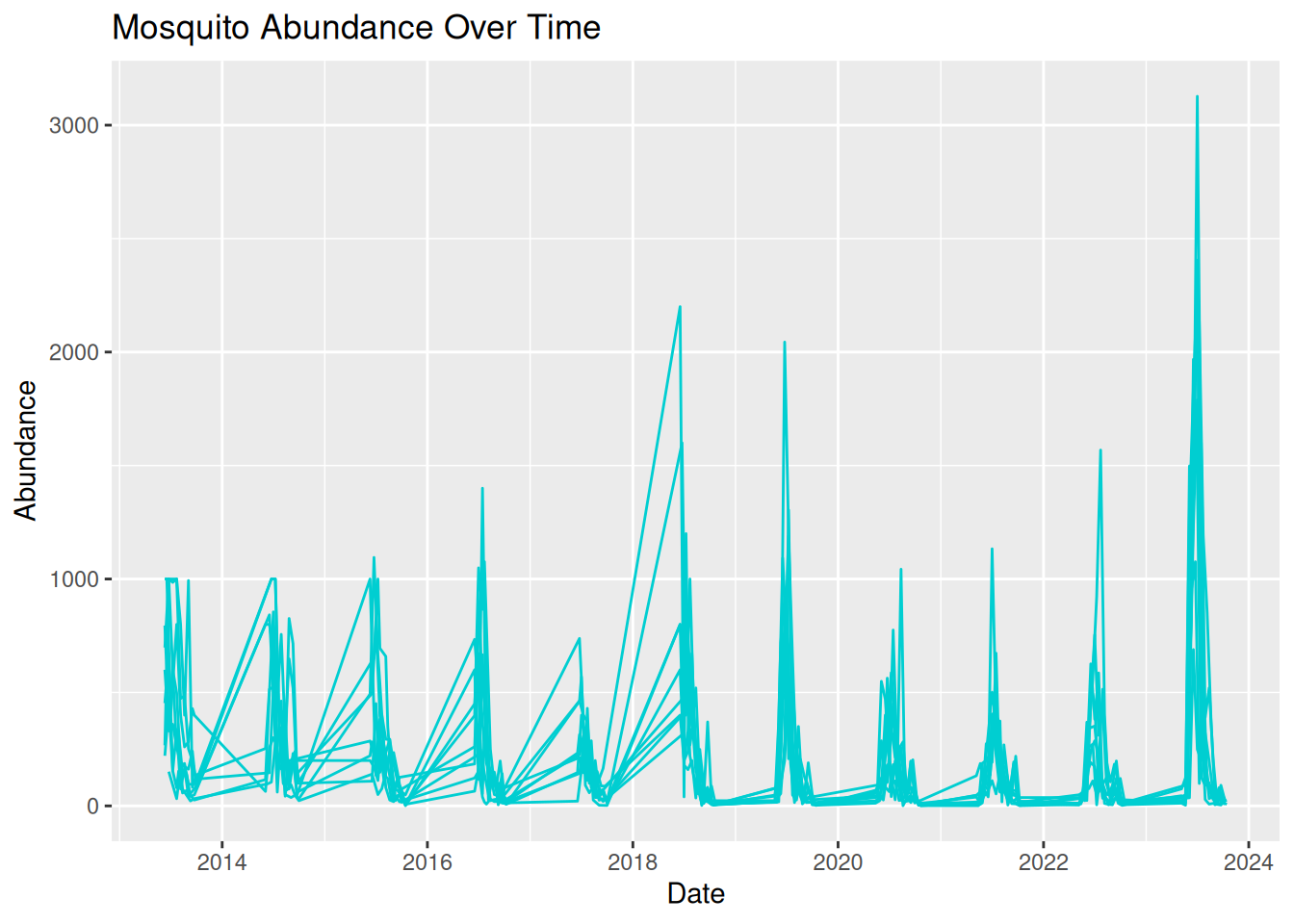
3.7.2 Graph 2
Dataset: group1_and_2_data.csv
Flawed code:
library("tidyverse")
group2_data <- read.csv("data/group1_and_2_data.csv")
group2_data_cadeo <- group2_data %>%
filter(sample_location == "Cadeo")
group2_data_cadeo$sample_start_date <- as.Date(group2_data_cadeo$sample_start_date)
group2_plot <- ggplot(group2_data_cadeo,
aes(x = sample_start_date, y = sample_value)) +
geom_col(fill = "darkturquoise") +
labs(
title = "Mosquito Abundance Over Time",
x = "Date",
y = "Abundance"
)
group2_plot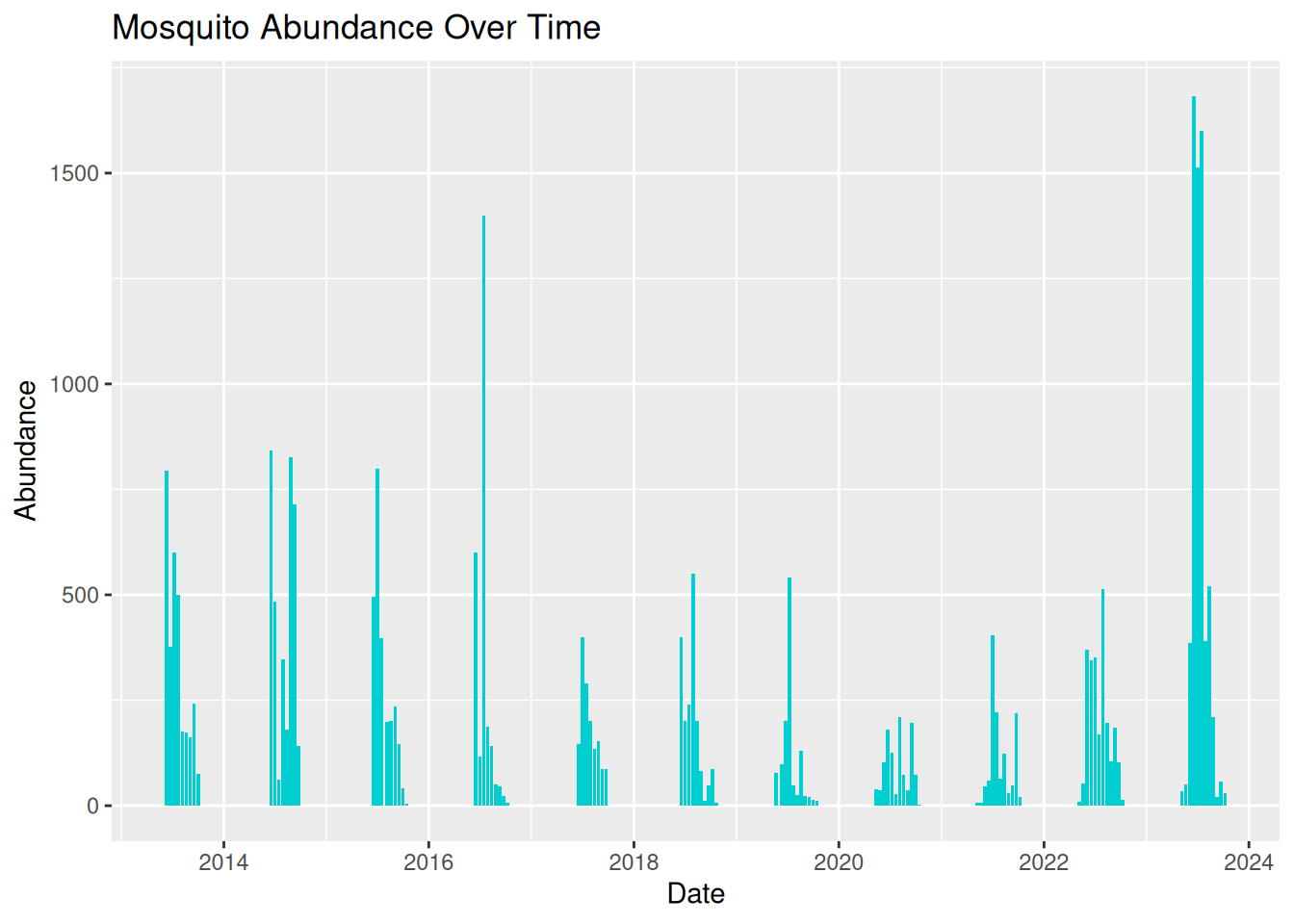
3.7.3 Graph 3
Dataset: group3_and_4_data.csv
Flawed code:
library("tidyverse")
group3_data <- read.csv("data/group3_and_4_data.csv")
group3_data$sample_start_date <- as.Date(group3_data$sample_start_date)
daily_abundance <- group3_data %>%
group_by(sample_location, sample_start_date) %>%
summarise(total_abundance = sum(sample_value, na.rm = TRUE),
.groups = "keep")
group3_plot <- ggplot(daily_abundance,
aes(x = sample_start_date, y = total_abundance, colour = sample_location)) +
geom_line()
group3_plot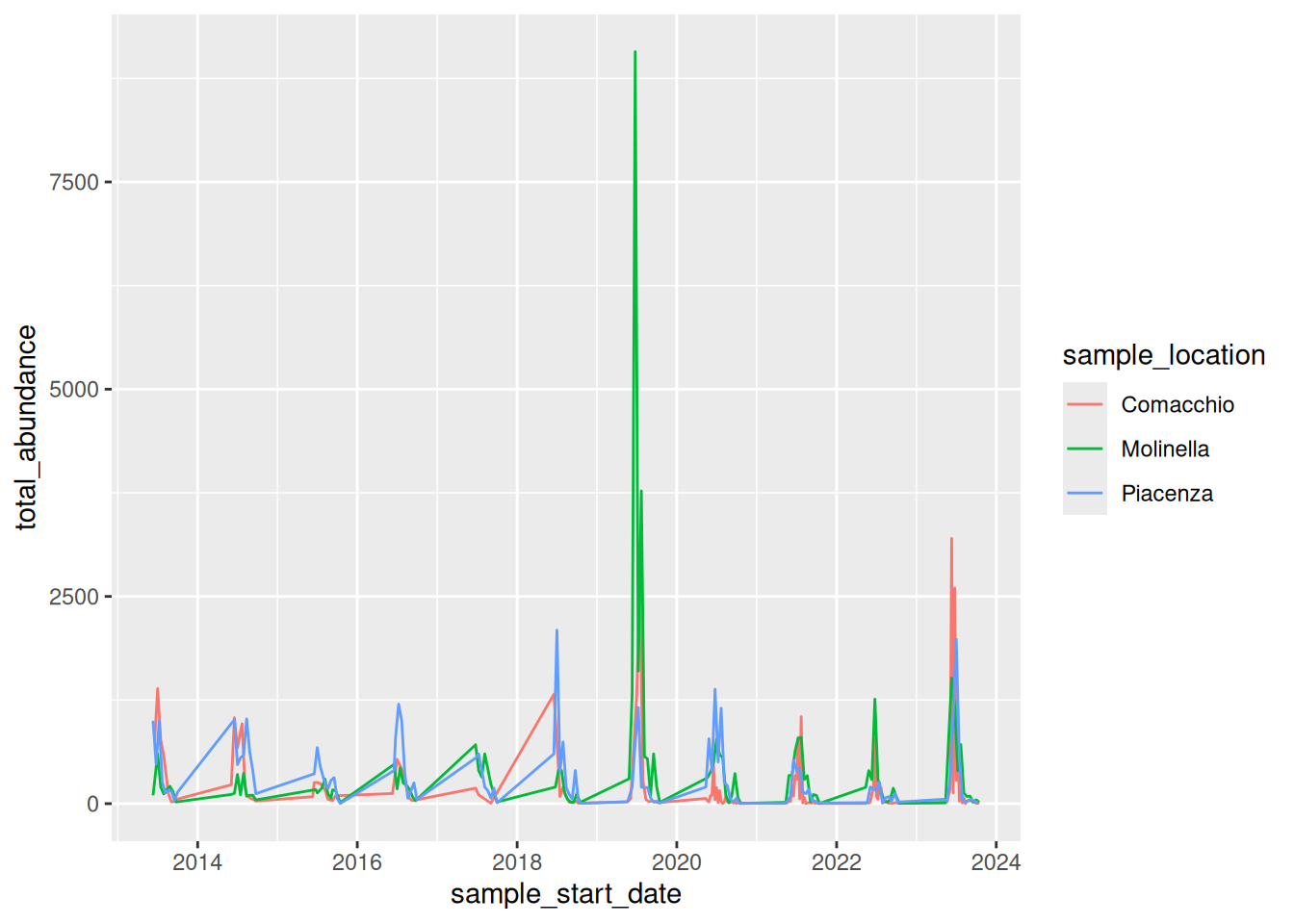
3.7.4 Graph 4
Dataset: group3_and_4_data.csv
Flawed code:
library("tidyverse")
group4_data <- read.csv("data/group3_and_4_data.csv")
group4_data$sample_start_date <- as.Date(group4_data$sample_start_date)
daily_abundance_all <- group4_data %>%
group_by(sample_start_date) %>%
summarise(total_abundance = sum(sample_value, na.rm = TRUE))
group4_plot <- ggplot(daily_abundance_all,
aes(x = sample_start_date, y = total_abundance)) +
geom_line(colour = "darkturquoise") +
labs(
title = "Mosquito Abundance Over Time",
x = "Date",
y = "Abundance",
colour = "Sampling Location"
)
group4_plot
#> Ignoring unknown labels:
#> • colour : "Sampling Location"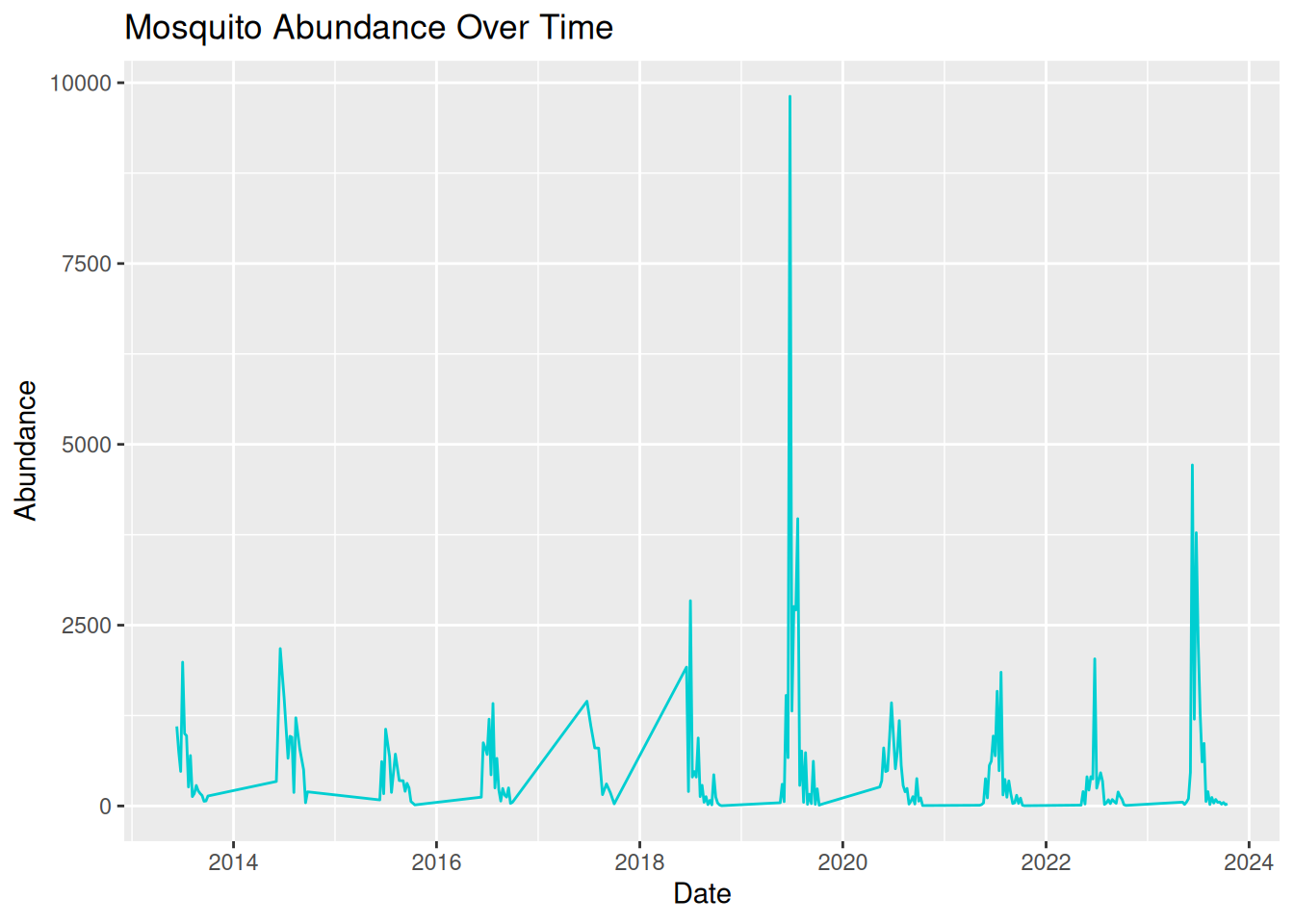
3.8 Communicating to Different Audiences
We can use visualisations to communicate patterns in our data to a variety of audiences. However, our visualisation and the language we use to discuss it need to be appropriately adjusted.
When designing a visualisation, it is therefore important to consider who the intended audience is and what information they need to best understand your data and findings.
Your audience may include academic researchers, policymakers, or members of the public, all of which may have different levels of technical understanding and communication needs.
Academic audiences are often more comfortable interpreting complex figures and statistics, and may expect details on variation and uncertainty in the data.
Policymakers typically prefer visualisations that clearly communicate relevant trends used to influence decision-making.
For public engagement activities, visualisations usually need to be more accessible and use simple language so the audience can understand what the graphic is communicating, without specialised knowledge.
Adapting visualisations to suit different audiences is an important skill for researchers who wish to communicate their findings effectively.
Tip: When designing visualisations for specific audiences, try to consider:
- The level of technical knowledge.
- How clearly the key findings are communicated.
- Any additional information needed to easily interpret the visualisation.
3.9 Visualisation Themes & Accessible Graphics
3.9.1 Themes
So far, we have focused on choosing appropriate plot types, developing visualisations with multiple data types, and using visualisations to identify patterns in your data. Effective visualisations should also consider how the visual design contributes to the interpretability and accessibility of a plot to various audiences.
In ggplot2, the visualisation design can be controlled using themes. Themes allow us to adjust non-data elements of a plot, including:
- Background colour
- Grid lines
- Text size and font
- Legend position
All of these help to improve the clarity and readability of a visualisation.
Themes can be applied to any ggplot using the theme() function or by using one of the existing ggplot2 theme presets. For example, we can apply theme_minimal(), a simple theme from ggplot2, to one of our existing plots:
daily_abundance_plot_goro <- ggplot(daily_abundance_goro, aes(x = sample_start_date, y = total_abundance)) +
geom_line() +
theme_minimal() +
labs(
title = "Abundance of Culex pipiens Over Time",
x = "Date",
y = "Abundance"
)
daily_abundance_plot_goro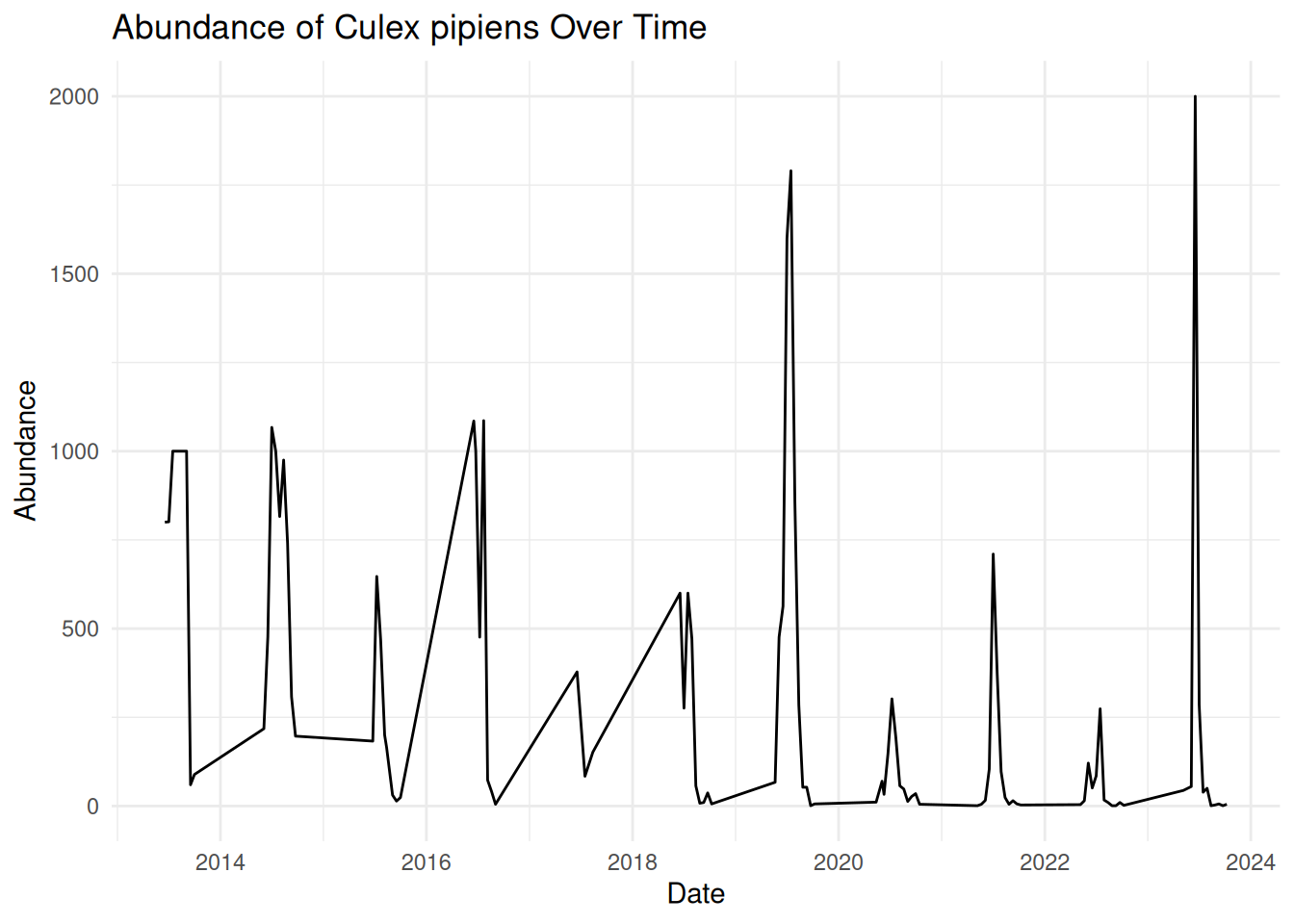
We can see that applying this theme removes the background shading and uses simple black and grey colours, resulting in a clean and easily readable visualisation.
ggplot2 has several themes you can use - some commonly used themes include:
Using consistent themes across visualisations can help to create a more professional and cohesive appearance. This is particularly useful when using visualisations to communicate data to various audiences, such as conference talks or publications.
3.9.2 Improving Visual Clarity
When we visualise our data, we want key patterns to stand out, particularly when presenting our data to others. We can achieve this by improving the contrast, for example, increasing the line width in a time series plot:
geom_line(linewidth = 1.2)Or changing point style in a scatter plot:
geom_point(shape = 17)Another simple method for improving visual clarity that people often forget is clear labels and titles. We have already learnt how to add these when using ggplot2:
labs(
title = "Abundance of Culex pipiens Over Time",
x = "Date",
y = "Abundance"
)Remember, visualisation labels should be clear and informative - make sure the title and axis are readable, and the audience understands what they are looking at. Consider the medium in which you want to share your visualisation - all text should be large enough to read on presentation slides, when printed, or when viewed on different screen sizes.
Earlier in this session, we saw how visualisation can quickly become overcrowded and difficult to interpret. Try to avoid visual clutter by:
- Reducing the number of variables displayed in one graphic
- Avoiding unnecessary layers.
- Using methods such as faceting to split plots into separate panels.
Using colours in your visualisations can be helpful, for example, to highlight different groups. However, colour can quickly reduce the clarity of your visualisation, particularly if you use bright or clashing colours with minimal contrast.
Tip: For best readability, remember to use dark lines or points on a light background. Try to use accessible colour palettes so that your visualisation is accessible to a wider audience.
3.9.3 Designing Accessible Visualisations
Accessibility is an important consideration when designing visualisations, particularly when communicating your data to diverse audiences. For instance, some viewers may have visual impairments, such as colour vision deficiencies, which can make certain visualisations difficult to interpret.
There are multiple principles which can help improve the accessibility of your visualisations. Some commonly used strategies to consider include:
1. Using accessible colour palettes - some colour combinations can be difficult to differentiate, such as red and green. ggplot2 includes viridis colour scales, which are designed to improve visual clarity and accessibility of visualisations: scale_colour_viridis_d()
2. Using multiple visual cues - using alternative visual cues ensures that all elements in your visualisations remain clear and visible without colour. Alternative options include line types, point shapes, and faceting.
3. Exporting visualisations - you may have noticed that throughout this workshop, we have saved our visualisations as pdf files. This format improves accessibility by allowing viewers to view details more clearly by zooming in without reducing image quality.
4. Providing alternative text (alt-text) - when sharing visualisations in digital formats, alternative text descriptions can be added so that screen reader users can access your visualisations.
Designing accessible visualisations improves inclusivity and results in clearer and more effective communication for all viewers.
3.10 Preparing for the Challenge Task
The final session of this training will provide an opportunity for you to independently apply the skills and concepts discussed throughout the Pre- and Live Session content, including:
- Selecting appropriate plot types.
- Clearly communicating patterns in the data.
- Considering the needs of different audiences.
- Applying effective visual design principles.
The Challenge Task will have multiple levels and is designed to encourage applied thinking. We encourage you to experiment with different approaches and discuss potential difficulties with each other.
We encourage you to have a go at the task on your own, but a walkthrough version will be released after a few hours, should you need additional guidance.
3.11 Conclusion
Throughout this workshop, we have explored how visualisations can be used to better understand and communicate VBD data.
We began by building simple abundance plots and then extended them to explore patterns across time, space, and species. We also discussed how visualisations can support hypothesis generation and how thoughtful design choices can improve the clarity and accessibility of scientific figures.
Effective visualisation is a valuable skill for researchers working with complex datasets. By carefully considering how data are represented, we can make patterns more visible, communicate findings more effectively, and support evidence-based decision-making in VBD research.